
RPAで自動化する処理として伝票などの管理を考えている方もいると思います。
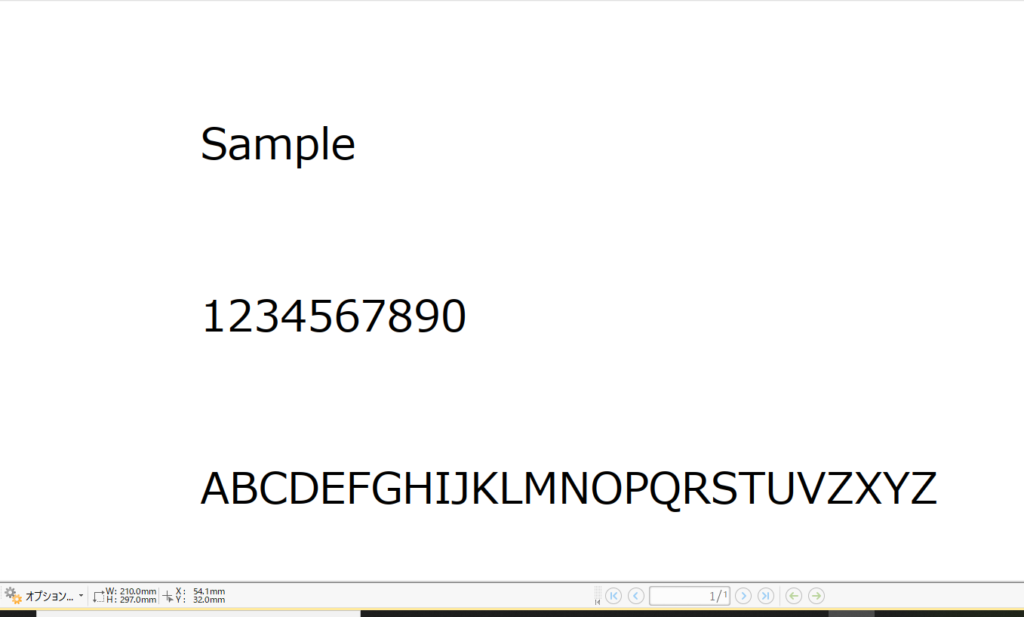
サンプルとして次のようなPDFファイルを準備しました。
なお、スキャナからの取り込みではなく、WORDからの直接作成です。
プロセスの構築
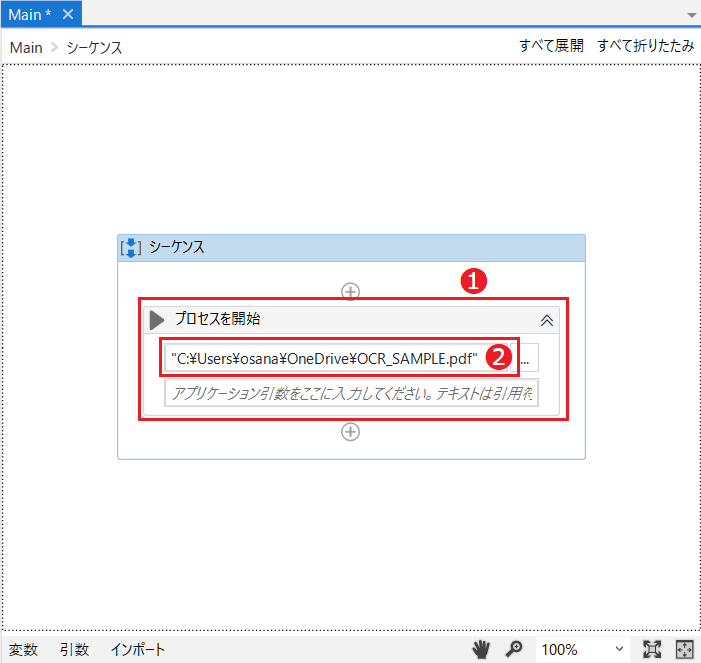
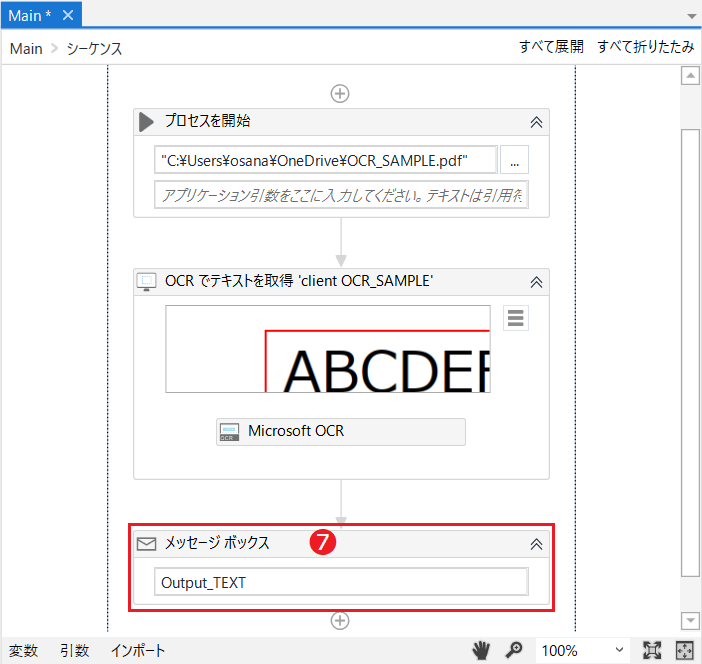
[プロセスを開始]のアクティビティ❶を配し、処理するファイルのフルパス❷を入力します。
[OCRでテキストを取得]のアクティビティ❸を接続し、❹をクリックします。
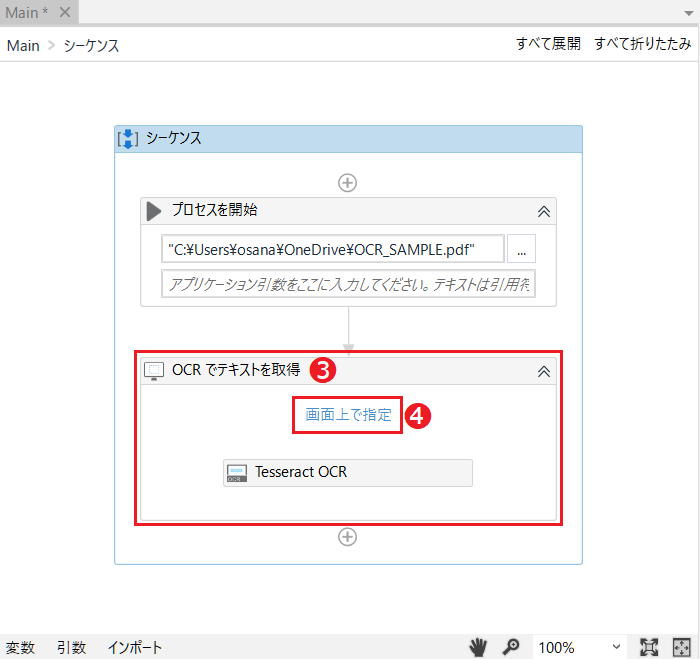
OCRの認識対象を選択する画面になりますが、デフォルトでは要素全体の設定になっています。
ここで、F3キー押すと自由に領域を選択できるようになります。ここではアルファベットを選択します。
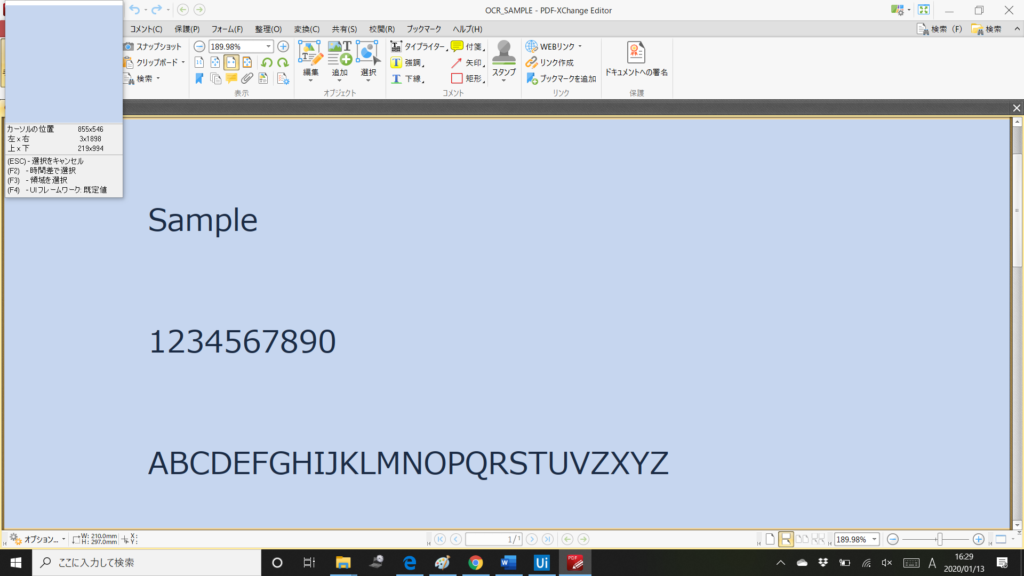
対象の選択を要素から任意に変更する部分を動画にしています。文章でわかりにくい方は参考にしてください。0:05付近でF3キーを押下してカーソルが変わっていることがわかります。
次のOCRエンジン❺を設定します。デフォルトではTesseract OCRが入っていますが、ここでは初心者向けのMicrosoft OCRに変更したいと思います。❺をアクティブにしてDelキーを押下すると現在設定のエンジンが外れます。
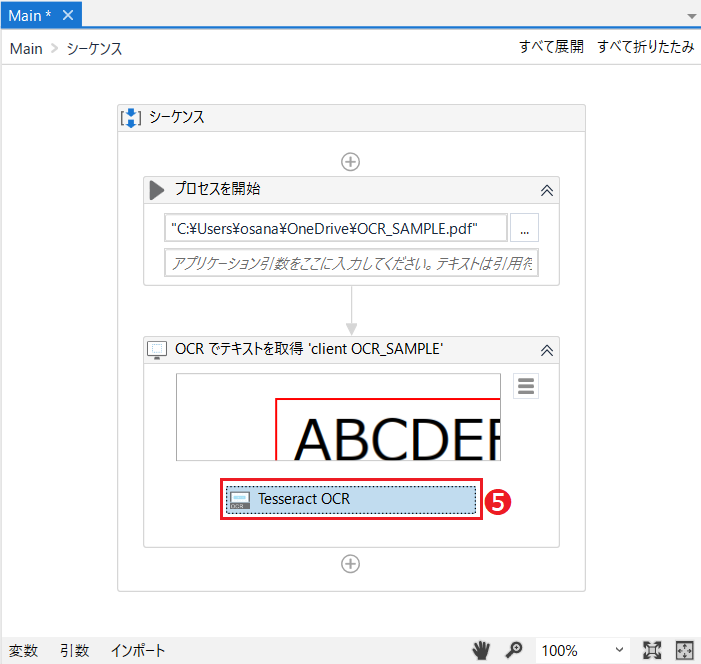
「 ここに OCRエンジンアクティビティをドロップ 」と表示されますので、アクティビティパネルからMicrosoft OCRをドラッグ&ドロップします。
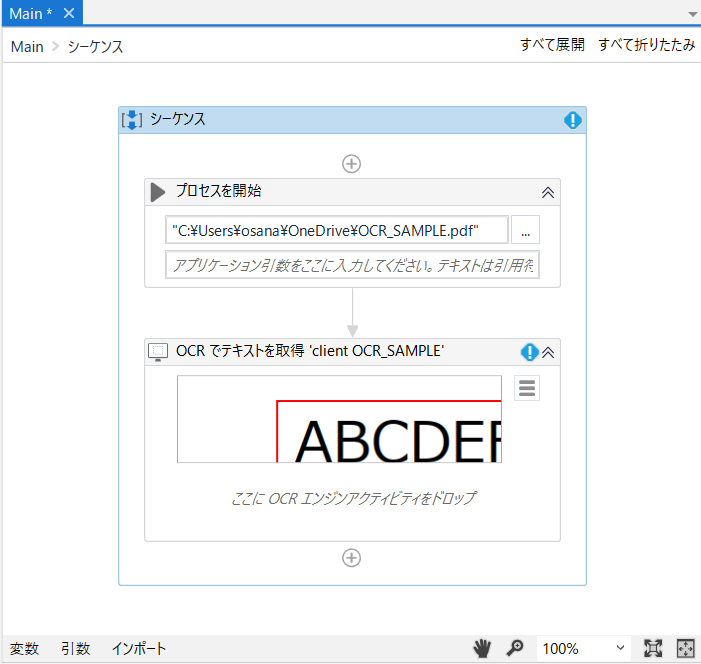
下のように、Microsoft OCRがエンジンとして入ります。
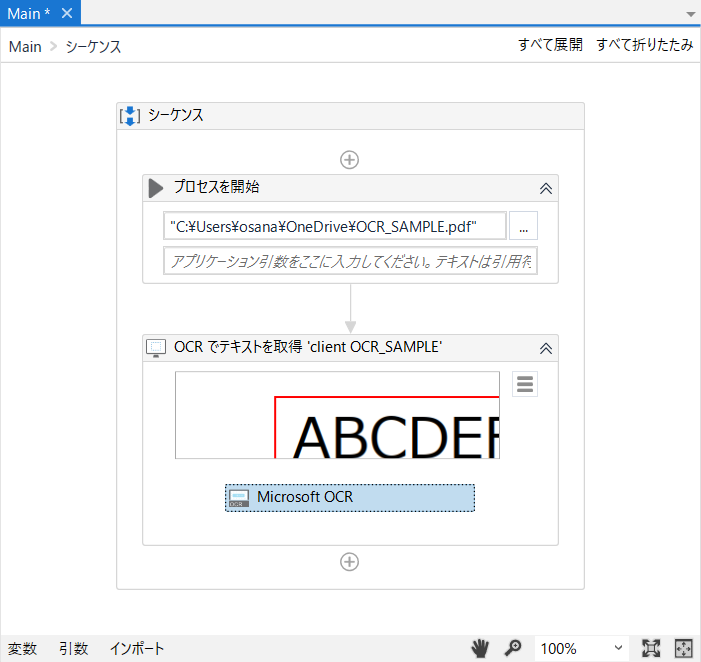
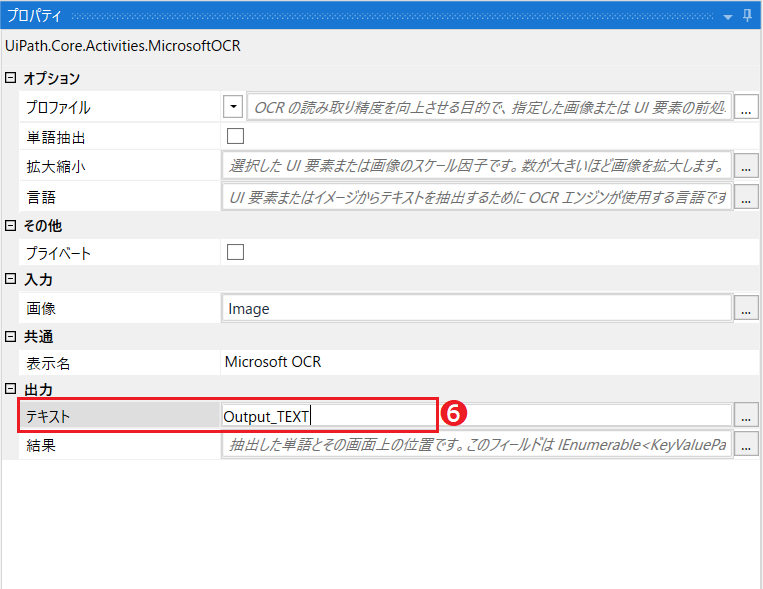
次にMicrosoft OCRのプロパティを設定します。認識した文字を、ここではOutput_TEXTと定義しました。
メッセージボックスを配置して、先に定義した変数Output_TEXTを表示❼します
実行した動画です。
最後のメッセージボックスにちゃんとアルファベットが表示されています。


コメント